01
Local-first OCR workbench
my-ocr
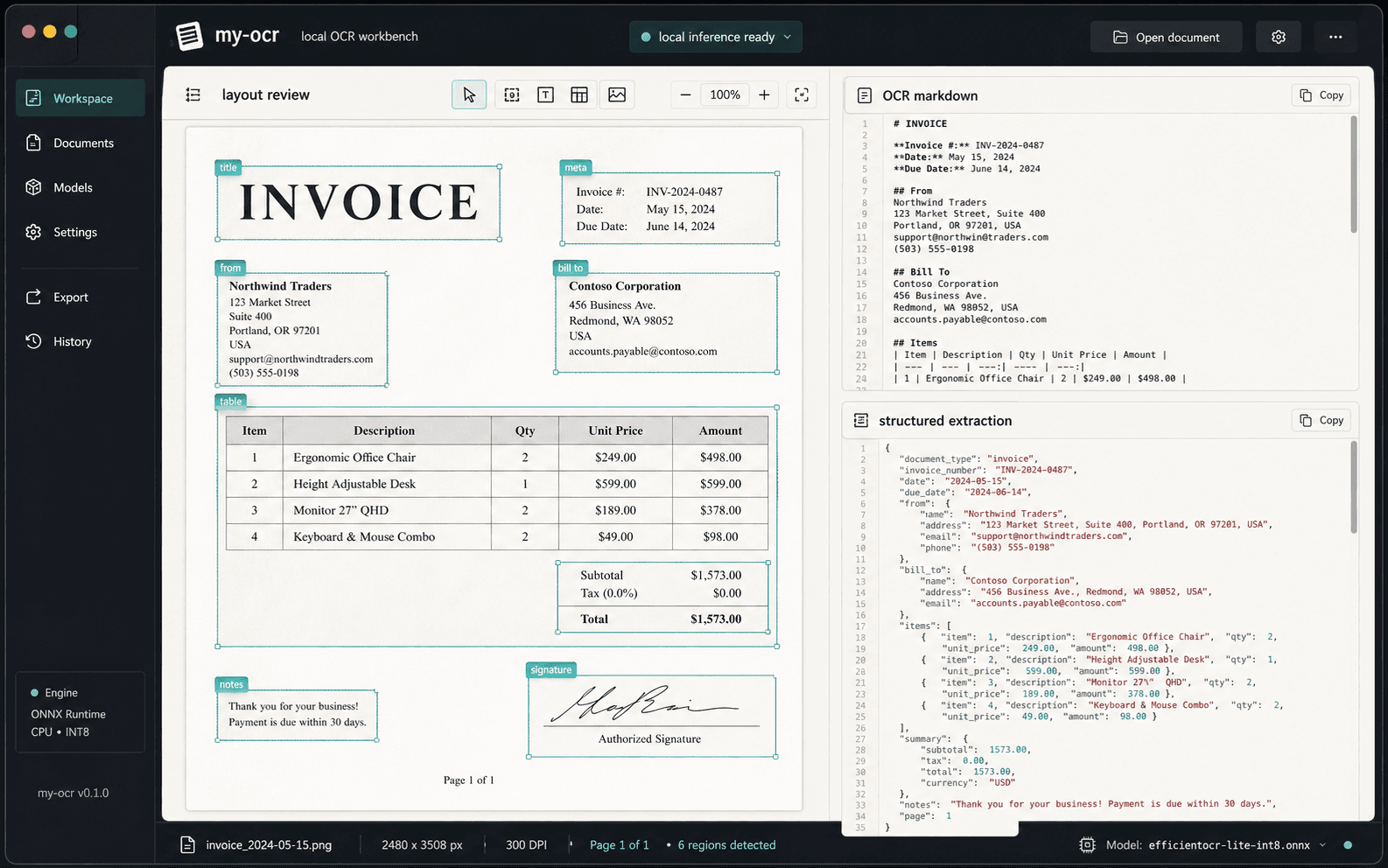
An OCR tool for PDFs and scanned images. You review and correct the detected layout before any extraction runs, so the output reflects what you actually marked up rather than what the model guessed.
Outcomes
- Layout regions are editable before OCR runs
- Exports to markdown, JSON, structured fields, and a run report
- Rule-based and LLM extraction can be compared on the same document
Context
- Runs locally by default via Ollama
- Any OpenAI-compatible or vLLM endpoint works as a drop-in
- Each run is stored in its own folder so results are reproducible
PythonFletOCROllamaPyMuPDFpytest